Indlæsningslag
Indlæsningslaget (ingestion layer) i FDAP har til opgave at læse data fra interne såvel som eksterne datakilder og opbevare dette i en data lake i henhold til den i FDAP anvendte konvention for bronze data. Data opbevares dels i det oprindeligt hentede format såsom strukturerede data i Parquet-, Excel- eller CSV-filer, semi-strukturerede data i JSON- eller XML-filer eller ustrukturerede data i billed- eller lydfiler. Data der ikke ankommer i Parquet format transskriberes til Parquet-format, således at al bronze-data er lettilgængeligt og kan aftages på homogen vis. Data hentes (pull) eller leveres (push) ind i en ankomstzone og flyttes efterfølgende til først en bronzezone og sidenhen en arkivzone med konfigurerbar opbevaringstid i hver zone. Indlæsningslaget er fuldt automatiseret og drives af konfiguration. Udvidelser tilføjes i form af dels såkaldte extractors til understøttelse af nye typer datakilder og dels såkaldte transcribers til understøttelse af nye kildedataformater. Det logiske design af indlæsningslaget beskrives herunder og tilgængelige implementation(er) af frameworket kan downloades nederst på siden.
Struktur & Flow
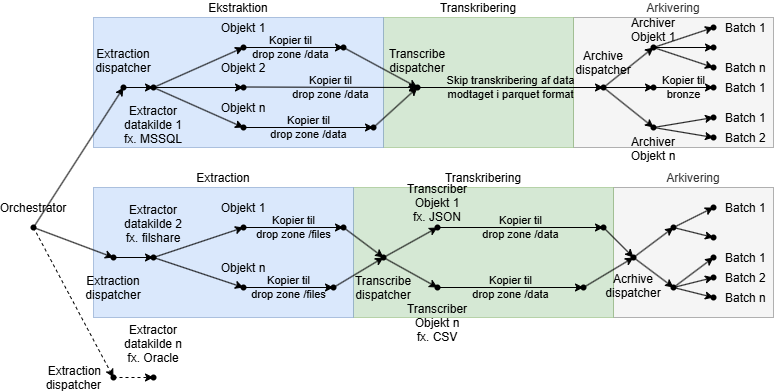
Datahandlingen i indlæsningslaget koordineres af en orchestrator og udføres parallelt for hver enkelt datakilde, der hver især behandles sekventielt i faserne ekstraktion (extraction), transkribering (transcription) og arkivering (archiving). I hver fase udvælger en dispatcher henholdsvis den påkrævede extractor, transcriber eller archiver til at udføre databehandlingen. Extractors understøtter specifikke typer af datakilder såsom MSSQL og Oracle databaser eller SFTP og SMB fil-servere, mens Transcribers understøtter specifikke kildedataformater såsom CSV- og Excel-filer og konvertering af disse til parquet. Objekterne i hver enkelt datakilde behandles parallelt under både ekstraktion, transkribering og arkivering.